本文是一份面向初学者的详细教程,指导你如何在配备 Intel Arc B580 显卡 的电脑上,通过 OpenVINO 官方优化框架,从零开始部署 Stable Diffusion 生图大模型。整个过程清晰直接,旨在绕开所有兼容性“暗礁”,让你首次尝试就成功生成图片。
为什么选择Stable Diffusion + OpenVINO方案?
选择 “Stable Diffusion + OpenVINO” 方案,对于使用Intel显卡的用户来说,核心原因是最大化利用官方生态,追求最直接、最稳定的部署体验。根据英特尔官方数据,在Arc显卡上,OpenVINO优化的SD模型生成速度比原生PyTorch快数倍,且内存占用更低。
准备工作
请确保你已准备好以下环境与资源:
| 项目 | 要求 | 检查点 |
|---|---|---|
| 操作系统 | Windows 10/11 64位 或 Ubuntu 22.04 LTS | 系统版本符合 |
| 显卡驱动 | 最新版 Intel Arc GPU 驱动程序 | 前往 Intel 官网下载 并安装 |
| Python | Python 3.10 或 3.11 | 在命令行输入 python --version 确认 |
| 存储空间 | 至少 16 GB 可用空间 | 用于存放模型和虚拟环境 |
| 网络环境 | 稳定连接,能访问 Hugging Face | 用于下载模型和库 |
分步部署教学
步骤 1:创建并激活 Python 虚拟环境
虚拟环境能隔离项目依赖,避免库版本冲突。
# 打开命令行(Windows CMD/PowerShell 或 Linux Terminal)
# 1. 创建虚拟环境,命名为 'sd_openvino'
python -m venv sd_openvino
# 2. 激活虚拟环境
# 在 Windows 上:
sd_openvino\Scripts\activate
# 在 Linux/macOS 上:
source sd_openvino/bin/activate
# 激活后,命令行提示符前会出现 (sd_openvino) 标识步骤 2:安装核心软件包
安装 OpenVINO 集成工具和基础的图像生成库。
# 升级 pip 工具
python.exe -m pip install --upgrade pip
# 安装 OpenVINO 与 Stable Diffusion 集成包
# 这将自动安装 openvino, transformers, diffusers 等所有依赖
pip install "optimum-intel[openvino,diffusers]" --extra-index-url https://download.pytorch.org/whl/cpu
# 安装额外的图像处理库
pip install Pillow matplotlib关键说明:optimum-intel 是 Hugging Face 官方提供的工具,它能无缝衔接 Diffusers 库与 OpenVINO 后端,是我们方案的核心。
步骤 3:下载并转换 Stable Diffusion 模型
我们将使用经典的 runwayml/stable-diffusion-v1-5 模型进行演示。
# 创建一个名为 download_convert.py 的 Python 脚本,复制以下代码:
from optimum.intel.openvino import OVStableDiffusionPipeline
import torch
# 1. 指定模型名称
model_id = "runwayml/stable-diffusion-v1-5"
# 2. 创建 OpenVINO 优化管道
# 此步骤会自动从 Hugging Face 下载原模型,并将其转换为 OpenVINO 格式
# 转换后的模型会默认保存在 './openvino_model' 目录
print("正在下载并转换模型,首次运行需要较长时间,请耐心等待...")
ov_pipe = OVStableDiffusionPipeline.from_pretrained(
model_id,
export=True, # 启用导出/转换
torch_dtype=torch.float16, # 使用 FP16 精度,节省显存并保持质量
)
# 3. 保存完整的本地化管道
save_path = "./stable-diffusion-1.5-openvino"
ov_pipe.save_pretrained(save_path)
print(f"模型转换完成,已保存至:{save_path}")运行此脚本:
python download_convert.py这是最耗时的一步,取决于你的网速,可能需要 20分钟到1小时。成功后,当前目录下会生成一个 stable-diffusion-1.5-openvino 文件夹,里面包含了优化后的模型。如果提示TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败,请使用魔法以便下载并转换模型。
步骤 4:编写图像生成推理脚本
现在,让我们用本地模型生成第一张图片。
# 创建一个名为 generate_image.py 的 Python 脚本,复制以下代码:
from optimum.intel.openvino import OVStableDiffusionPipeline
from PIL import Image
import time
# 1. 加载本地已转换的 OpenVINO 模型
model_path = "./stable-diffusion-1.5-openvino"
print("正在加载优化模型...")
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_path)
# 2. 定义生成参数
prompt = "A beautiful sunset over a mountain lake, digital art, detailed, 4k" # 你的提示词
num_inference_steps = 25 # 推理步数(越多质量可能越高,但越慢)
num_images = 1 # 生成图片数量
# 3. 开始生成并计时
print(f"正在生成图片,提示词: '{prompt}'")
start_time = time.time()
images = ov_pipe(
prompt,
num_inference_steps=num_inference_steps,
num_images_per_prompt=num_images
).images
end_time = time.time()
print(f"图片生成完成!耗时:{end_time - start_time:.2f} 秒")
# 4. 保存图片
for idx, image in enumerate(images):
filename = f"output_{idx}.png"
image.save(filename)
print(f"图片已保存为:{filename}")
# 如果你在本地有图形界面,可以直接显示
# image.show()步骤 5:运行生成!
在命令行中执行:
python generate_image.py如果一切顺利,你将看到进度信息,并在脚本同目录下得到名为 output_0.png 的图片。
恭喜!你已成功在 Intel Arc 显卡上部署并运行了 Stable Diffusion。
高级技巧与性能调优
成功运行基础流程后,可以通过以下调整获得更好体验:
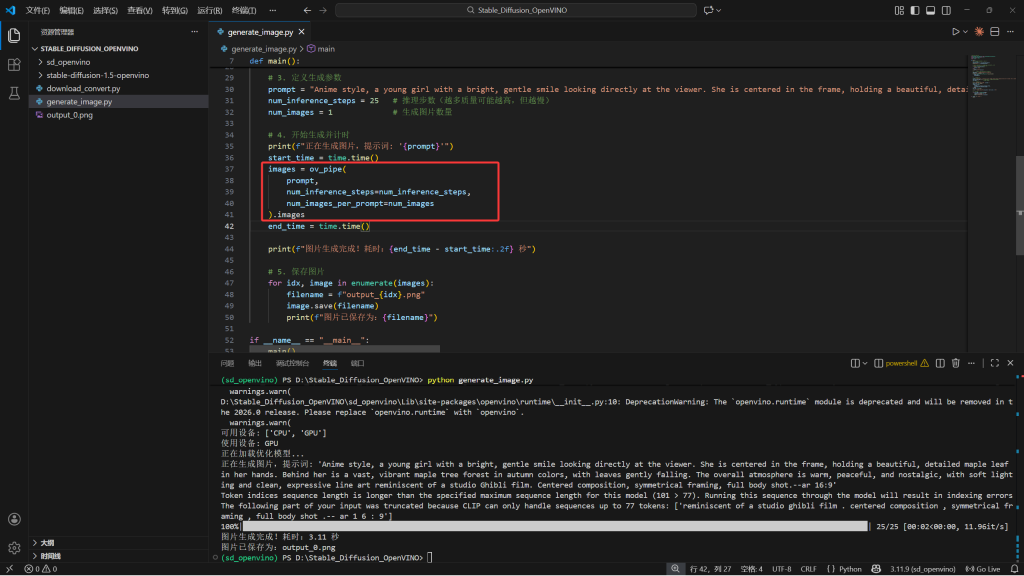
1.启用 GPU 加速:默认可能使用 CPU。确保 OpenVINO 调用了你的 Arc 显卡。
将这段代码替换generate_image.py里的全部代码
# generate_image.py
from optimum.intel.openvino import OVStableDiffusionPipeline
from openvino.runtime import Core
from PIL import Image
import time
def main():
# 1. 初始化OpenVINO核心,检查可用设备
core = Core()
available_devices = core.available_devices
print("可用设备:", available_devices)
# 选择设备,如果可用设备中有GPU,则使用GPU,否则使用CPU
# 注意:Intel Arc显卡应该被识别为GPU
if "GPU" in available_devices:
device = "GPU"
else:
device = "CPU"
print(f"使用设备: {device}")
# 2. 加载本地已转换的 OpenVINO 模型,并指定设备
model_path = "./stable-diffusion-1.5-openvino"
print("正在加载优化模型...")
ov_pipe = OVStableDiffusionPipeline.from_pretrained(
model_path,
device=device
)
# 3. 定义生成参数
prompt = "Anime style, a young girl with a bright, gentle smile looking directly at the viewer. She is centered in the frame, holding a beautiful, detailed maple leaf in her hands. Behind her is a vast, vibrant maple tree forest in autumn colors, with leaves gently falling. The overall atmosphere is warm, peaceful, and nostalgic, with soft lighting and clean, expressive line art reminiscent of a studio Ghibli film. Centered composition, symmetrical framing, full body shot." # 提示词:一个手拿着枫叶的少女面对镜头微笑,背后是一片枫叶林,动漫风格,少女在屏幕中间
num_inference_steps = 25 # 推理步数(越多质量可能越高,但越慢)
num_images = 1 # 生成图片数量
# 4. 开始生成并计时
print(f"正在生成图片,提示词: '{prompt}'")
start_time = time.time()
images = ov_pipe(
prompt,
num_inference_steps=num_inference_steps,
num_images_per_prompt=num_images
).images
end_time = time.time()
print(f"图片生成完成!耗时:{end_time - start_time:.2f} 秒")
# 5. 保存图片
for idx, image in enumerate(images):
filename = f"output_{idx}.png"
image.save(filename)
print(f"图片已保存为:{filename}")
if __name__ == "__main__":
main()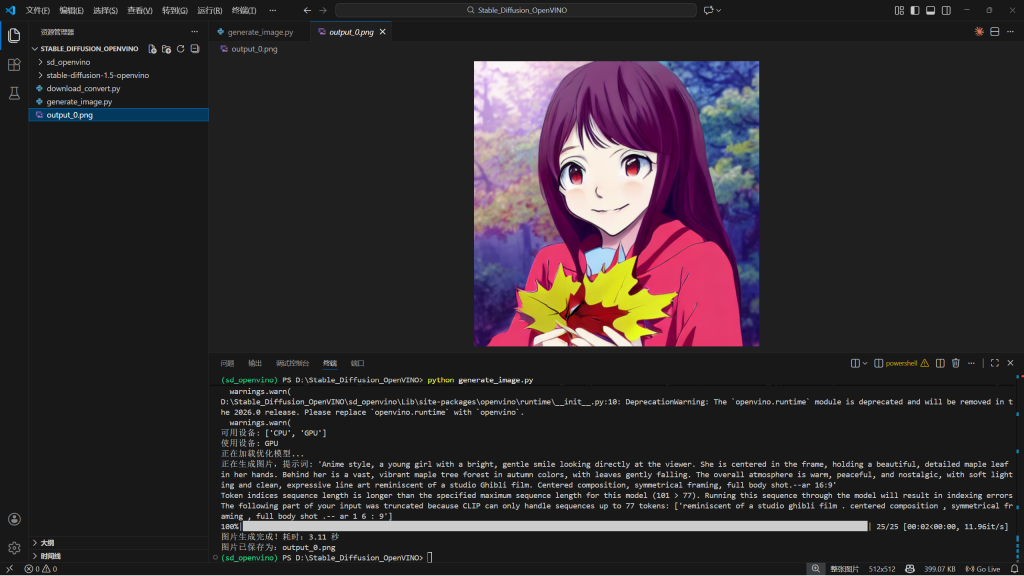
2.优化显存与速度:在你的 显存 范围内调整关键参数。
将这段代码替换generate_image.py里对应的代码(在开始生成里面),再根据自己显卡合理调整。
images = ov_pipe(
prompt,
num_inference_steps=20, # 20-30步是速度与质量的平衡点
guidance_scale=7.5, # 提示词相关性,7-9较常见
height=512, # 生成图片高度
width=512, # 生成图片宽度
num_images_per_prompt=1, # 同时生成多张会大幅增加显存
).images3.尝试更强大的模型:成功运行 v1.5 后,你可以用同样方法部署 Stable Diffusion XL。
只需在转换脚本中将 model_id 改为 "stabilityai/stable-diffusion-xl-base-1.0"。注意,SDXL 模型更大,生成时建议将分辨率设为 1024x1024,并密切监控显存占用。
故障排查
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 转换模型时下载失败 | 网络连接问题 | 使用国内镜像源,或手动从 Hugging Face 下载模型文件后再从本地转换 |
| 运行时报内存不足 | 同时生成图片过多或分辨率过高 | 减少 num_images_per_prompt,降低 height 和 width |
| 生成速度很慢 | 可能未正确调用 GPU | 按“高级技巧”部分检查并设置 device="GPU" |
| 生成的图片是黑色或噪点 | 模型未正确加载或精度问题 | 确保转换和加载时 torch_dtype 一致(如都用 float16) |
如果遇到“算子不支持”等复杂错误,通常是由于模型中有极少数操作未在 OpenVINO 中实现。此时,可以尝试在 from_pretrained 方法中添加 compile=False 参数,但可能会影响性能。
现在,你拥有了一套完全在本地运行、由你的 Intel 显卡驱动、且经过官方优化的生图 AI 系统。接下来,尽情探索不同的提示词和模型,享受创作的乐趣吧!